Gensim word2vec python tutorial
Gensim word2vec python tutorialThe python gensim word2vec is the open-source vector space and modeling toolkit. The implementation is done in python and uses Scipy and Numpy. It is one of the techniques that are used to learn the word embedding using a neural network. The input is text corpus and output is a set of vectors. The natural ability to understand the people are done by human begins and says in response. It is a technique for creating the vectors of word representation that will capture syntax and schematics. The vectors are used to represent a word in features as, The addition and subtraction of vectors show how to word semantics are captured. The similar words have the same word vectors. The issue in the word2vec algorithm is that they are not able to add more words to vocabulary after training. It returns some astonishing results and can maintain the semantic relation. They will have certain advantages over a bag of words.
It returns the schematic meaning of words in a document and the advantage is that a size of the embedding vector is very small.
The ability is developed by interacting with people and society.
The languages which human use for interaction are called natural languages.
Word2vec is the embedding technique used for word vector with python gneiss library.
The idea of the word2vec is simple and meaning is interfered with by the company.
The word2vec is a semantic learning framework that uses a shallow neural network to learn word/phrases.
Word2vec is used to learn the context and place them together in the same place.
First we import and get logged,
1) Import gzip
2) Import gensim
3) Import logging
Use of gensim:-
It is a neural word that is useful in natural language processing (NLP). Some techniques have only one representation per word and a single word and have multiple meanings. The neutral approach and the focus on application to consume the NLP algorithm. Sense2Vec will present a novel approach that addresses by modeling multiple embedding each word.
They will have many features as,
Memory independent:-The training does not reside in RAM at a time it can process large, webscale with ease.
They will also provide the I/O wrappers and converters as the data formats.
The gensim will implement the vector space algorithm and include Tf-Idf LDA.
They will provide similarity quires for document in semantic representation.
First step is to check the machine is working or nit.
Then install the gensim library. We will also satisfy that device is ready for gensim.
Sudo pip install
Dataset:-
It is good and the secret of getting word2vec is to have a lot of data and lost text data.
Word2vec is initiated and passed the reviews and read.
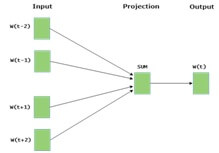
CBOW (continuous bag of words):-
It is predicted to current words within a specific window.
The input layer will contain a context word and an output layer.
Skip gram:-
It predicts surrounding context words within the window and given the current word.
The input layer will contain the current word and the outer layer contains the context word.
gensim word2vec Parameters:-
Size:-the number of dimensions of embedding as the length of the dense vector to represent each token.
Window:-the maximum distance between target and word around the target word.
Min_count:-the minimum count of words that are used when training the model as an occurrence less than the count which is ignored.
Workers:-the number of threads that use while is training.
Sg:-the training either CBOW (0) or skip-gram (1).
gensim word2vec Example:-
from gensim.models import KeyedVectors
filename = 'GoogleNews-vectors-negative300.bin'
model = KeyedVectors.load_word2vec_format (filename, binary=True)
result=model.most_similar (positive= [‘woman’,’king’], negative= [‘man’], topn=1)
print(result)
Output:-
[(‘queen’, 0.7118192315101624)]
Advantages:-
- The data is fed into model in online way and need little preprocessing so it require less memory.
- The mapping is between the target word to context word and sublinear relationship into the vector space of words.
- The idea is intuitive and transform unlabeled raw corpus into labeled data.
- It’s simple for freshmen to understand and implement.
Disadvantages:-
- It is the sublinear relationship and not explicitly defined.
- The model is difficult to train and use softmax function as the number is too large.
- The vectors which are NEG not distributed uniformly, located within the cone vector space.























