Scikit learn tutorial for beginners | Machine learning scikit learn tutorial
Scikit learn tutorial for beginners | Machine learning scikit learn tutorial : In this Scikit Learn Tutorial for beginners, we will use MLPClassifier to learn machine learning in Python. Scikit learn is a free machine learning library for Python. Learn to code python via machine learning with this scikit learn tutorial. The scikit was developed by David cournapeau as the Google summer of code in 2007. Nextly mathhthieu joined the project and started to use the work. In year 2010 INRIA got involved and release was published in late January 2010. The python programmers have the best library to build ML applications. Scikit learn is used as a simple interface with many examples. This library is used for dimensionally reduction, feature extraction, etc. The interface is consistent and not easy to use buy easy to construct. The data set contains numerical data used in a numerical manner. Scikit learn is a data mining library used in the python language. The library will provides powerful array and tools as select, reduce, etc.
Scikit learn
The scikit is modern ML and powerful language. It is a great tool used for data analysis.
This library is used to organize and identify the tools. Also provides the model support for any problem.
It is the free ML library used in the python programming language.
And useful tools for data mining and analysis for commercial use.
The scikit works with the numerical libraries and python scientific as numpy and scipy.
The scikit is the open library used in the ML applications.
The scikit learn library is used for beginners because it offers high level interface for many operations.
Here we will study how to represent the data with scikit learn using the tables of data.
It will support the algorithms as SVM, KNN, etc.And built on the top of numpy.
It is easy to use and provide a good result. It will not support the parallel computation and possible to run a deep learning algorithm.
For the use of a robust library, you can use ML in the production system.
Scikit learn will range the unsupervised and supervised learning using the interface python.
The scikit library is built on scipy known as the “scientific python” and installed before you use scikit learn.
It is used to build models and used for reading, manipulation.
The scikit will consist algorithm and the libraries and contains some packages as,
- Scipy(scientific python)
- Numpy
- Matplotlib
Features of scikit learn are as follows :-
Cross-validation :- Used for estimating the performance of supervised on unseen data.
Clustering:-
It is used for grouping unlabeled data as the KMeans.
Dimensionally reduction:-
Used for the reducing number of attributes in data for visualization, summarization and, feature such as component analysis.
Feature extraction:-
Used for defining attributes in the image and text data.
Ensemble method:-
Also used for the prediction of the multiple supervised models.
Functionality of scikit learns will provide:-
- Classification will include K nearest Neighbors.
- The regression will include linear and logistic regression.
- The cluster will include k-mean and k means++.
- Preprocessing includes the min and max normalization.
The data set list used in scikit learns are as follows:-
- Diabetes Dataset.
- Iris plants Dataset.
- Boston prices dataset.
- Digits dataset.
- Breast cancer.
- Wine recognition dataset.
Scikit learn problem solution:-
It helps in the data scientist and organizes the work through solution as,
- Fit the data into model to train and then test.
- Choose the Machine algorithm based on the data set.
- Tuning model through iterations and result observation.
- Strive for accuracy using the build in method that will support the predictive model.
While loading the data set to scikit we have to consider the points as,
- Create the object separately and response.
- Ensure features and response has only numeric values.
- The feature and response have numpy ndarray.
- They should be in form of arrays and should have shape and size.
Requirement to work with data in scikit learn:-
Target variable=dependent variable=response variable.
Sample=record=instance
Feature=predictor=independent variable.
Download and install scikit learn Python :-
1: Mac or windows using anaconda:-
We should refer the http://www.guru99.com/download-install-tensorflow.html.
If you install scikit with conda follow steps for the updating:-
- Activate the hello-tf
- Remove scikit learn using conda command. Conda will remove the scikit learn.
- Install scikit learn along with libraries,
Conda install-c anaconda git
pip install h5py
pip install cython
2: AWS:-used over AWS and refer the docker image that has preinstalled the scikitlearn.Then to use developer version use the Jupyter command.
import sys
Dependencies that scipy will require are:-
Python(>=3.5)
Numpy (>=1.11.0)
Scipy(>=0.17.0)
Joblib (>=0.11)
If already you are working on installation if scipy and numpy then the easiest way is to learn using the pip,
pip install –U scikit-learn
or conda:
conda install scikit-learn
Installations steps are as follows:-
Step1: Installing python:
- We can easily install python from any link.
- Make sure that we install the latest version as above 2.7.
- Then we will need to check if python is available for use of command line.
Syntax:-
Python
Step 2: Installing NumPy:-
The numpy package is used to provide the support and perform numerical computations.
Then download the installer of numpy from link and run it.
http://sourceforge.net/projects/numpy/files/numpy/1.102/
Syntax:-
pip install numpy
Step 3: installing the scipy:-
It is open source library used to perform the scientific computation and the technical computations.
Then download the scipy install using the link as follows,
http://sourceforge.net/projects/scipy/files/scipy/0.16.1/
Syntax:-
pip install scipy
Step 4: Installing Scikit-learn:-
Using the pip to install scikitlearn use the command as,
Pip install scikity-learn
Importing the dataset:-
Basically, scikit-learn has the dataset and needs to download from any source.
It is also used to import the data set directly before we import scikit learn and pandas using the following commands,
import sklearn
import pandas as pd
After the process of successful importing sklearn we can easily import data set using command as,
From sklearn.datasets import load _iris
We import iris plant dataset from sklearn and need to import pandas because we are importing data into pandas and use head (), tail () function.
Converting pandas dataset into a pandas data frame,
iriss=load_iris ()
df_iris=pd.DataFrame (iriss.data, column=iriss.feature_names)
Scikit learn as loading the dataset:-
Let us load the dataset named as the iris. It is the dataset of flowers and contains 150 flowers of different measurements.
Example:-
from sklearn import datasets
iris=datasets.load_iris ()
print(iris.data.shape)
Here we print the shape of data and print the data and run the code,
Output:-
>python3 load, py
(150, 4)
>
Scikit learn SVM:-
We create the estimator and call the method as follows,
Example:-
from sklearn import svm
from sklearn import datasets
iris=datasets.load_iris ()
clf=svm.linearsvc ()
clf.fit (it=iris.data, iris.target)
clf.predit ([[5.0, 3.6, 1.3, 0.25]])
Output:-
[[0.184 0.451 -0.807 -0.4507]
[0.05 -0.89 0.405 -0.93]
[-0.8 -0.98 1.3 1.8]]
Scikit learn linear regression:-
Create the models using scikit-learn now see example below,
from sklearn import linear_model
reg=linear_model.linearRegression ()
reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
print(reg.coef_)
Output:-
[0.5 0.5]
K-nearest neighbor classifier:-
Below given example will give the classification of algorithm and the classifier use the algorithm based on ball of trees to represent samples,
Example:-
from sklearn import datasets
iris=datasets.load_iris ()
from sklearn import neighbours
Knn=neighbours.KNeighboursClassifier ()
knn.fit (iris.data, iris.target)
result=knn.predict ([[0.10, 0.2, 0.3, 0.4]])
print(result)
Output:-
[0]
Kmeans the clustering:-
It is the clustering algorithm and set divided into k cluster and observation to cluster.Example:-from sklearn import cluster, datasetsiris=datasets.load_iris ()k=3k_means=cluster.kMeans (k)k_means.fit (iris.data)print (k_means.labels_ [: 10])Output:-[111112222200000][000001111122222]Like other programming language the user face problem having to choose multiple implementations of same algorithms.
Uses of scikit learn:-
- Mendeley
- Telecom
- Weber as a user of the library.
- It is called as an open source and used by professionals in the company.
- It wills the solution in little line code.
- It should be paired with DA and DV libraries.
Data as a table:-
The table is two-dimensional grids which have rows that will represent the element of the dataset.
The column will represent the qualities of each element.
Example:-
import seaborn as sns
iris=sns.load_dataset (‘iris’)
iris.head ()
Output:-
|
Sepal_length |
Sepal_width |
Petal_length |
Petal_width |
species |
0 |
5.1 |
3.5 |
1.4 |
0.2 |
setosa |
1 |
3.0 |
3.0 |
1.4 |
0.2 |
setosa |
2 |
4.7 |
3.2 |
1.3 |
0.2 |
setosa |
3 |
4.6 |
3.1 |
1.5 |
0.2 |
setosa |
4 |
5.0 |
6.0 |
1.4 |
0.2 |
setosa |
Now the rows of the data refer to single flower and number of rows is a total number of flowers in the dataset.
It will refer to rows of the matrix as samples and number of rows as n_samples.
Then each column of data will refer a quantitative piece of information and describe the sample.
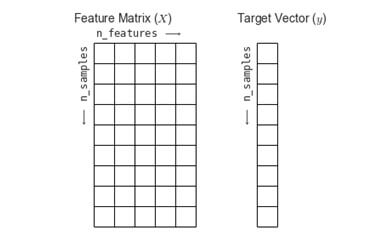
Feature matrix:-
The table will make clear information of two-dimensional arrays or the matrix.
This is called the feature matrix. Then the matrix is stored in name X.
It has the shape [n_sampkes, n_features contain the numpy array].
The feature will refer to the distinct observations that will describe the sample in quantities manner and real-valued.
Target array:-
After feature matrix, we work with target array which calls y.
It is the one-dimensional array with the length of n_samples and contains the numpy arrays in series.
It has continuous values while some scikit learn will handle the target values in the form of two-dimensional arrays.
Example:-
Import seaborn as sns;
Sns.set ()
Sns.pairplot (iris, hue=’species’, size=1.5);
The use of scikit learn we extract the matrix and target array from the data frame,
X_iris=iris.drop (‘species’, axis=1)
X_iris.shape (150, 4)
Y_iris=iris [‘species’]
Y_iris.shape (150,)
The API of scipy is designed with guidelines:-
- Inspection:-The specified parameter values are public attributes.
- Consistency:-The objects share a common interface from limited set of methods with documentation.
- Composition:-The ML task can be expressed as a sequence of fundamental algorithms and use the possible algorithms.
Classification with the scikit-learn:-
Visualize, parse, and load the data:-
The data is an important factor to start any project in ML.
The scikit learn to contain the package called sklearn. Dataset which helps us in the task.
The dataset is loaded in program and separated into test sets,
Example:-
From sklearn.datasets import load_iris
From sklearn.model_selection import train_test_split
Iris_dataser=load_iris ()
X, y=iris_dataset.data, iris_dataset.target
X_train, x_test, y_train, y_test=train_test_split(x, y, test_size=0.25, random_state=31)
Now dataset is loaded into program and look in samples of data.
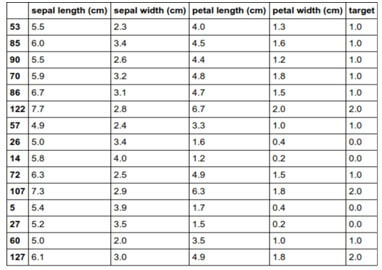
Let’s print 10% of the dataset in tabular visualization.
Example:-
import numpy as np
import pandas as pd
df=pd, DataFrame (data=np.c_[x, y], columns=iris_dataset [‘feature_names’] + [‘target’])
df.sampe (fac=0.1)
Output:-
Advantages of the scikit-learn:-
- Easy to use:-It is popular because of the scikit learn because it is easy to use.
- BDS license:-It is BDS license hence there is minimal restriction on the use and distribution of the software and make it free to use.
- Extensive use in the industry:-Used by various organizations and identify the activities and much more.
- Algorithm flowchart:-The algorithm is used here as the flowchart of the values.























