Selenium web scraping python tutorial | python selenium web scraping example
Selenium web scraping python tutorial : learn python selenium web scraping example with details. In this tutorial, we are going to explain the use of selenium web scraping in python. It is the technique for extracting the information/data from the given websites. In the python programming, it is used to scrap the data from the web in an efficient and quick manner. A tool is used to unstructured data on the web into the structured and readable data for analysis. The selenium tool comes for automating the websites and help web scraping for sites that require JavaScript. It is also called as the automated process in which the application will process HTML and extract the data for manipulation. Also used for converting one web page into another web page.
Web scraping with Beautiful Soup :-
It will explain the fundamentals of the web scraping as,
- To explore the web page structures and usage of developer tools.
- Used to make HTTP request and get HTML response.
- Also to get the structured information using the beautiful Soup.-
How the web scraping is used :
It will help us to extract the large volumes of data about products, people, and customers.
It is difficult to get information on a large scale using the data collection method.
It uses data which is collected from a website such as e-commerce portal also social media to understand customer behavior.
Why selenium? Beautiful soup is enough?
The scraping with python requires to use the beautiful soup.
It is the powerful library that will make scraping easy to implement.
But the problem is that it will only carry the scraping.
The exact view is seen from the web page source .Selenium will automate interaction from python programming and the data is rendered by automating button links with selenium using beautiful soup.
Selenium:-
The selenium is a simple process used to automate the web browser.
The need for automating the same task on the website can be done by the selenium.
Selenium is the best tool used nowadays for the automation of task.
It is used for many purposes as web scraping etc.
The websites run at the client-side and present data in a synchrous way sometimes it may cause an issue while trying to scrape the sites.
It allows the extraction of data and usable configuration to store data.
The collected data is part of the pipeline where it is treated as the input for other programs.
The selenium comes with handy and wants to scrape data from JavaScript and content WebPages.
To install the simply run,
pip install pandas
Installing selenium:-
It is the web browser automation tool also used for the web applications as testing and allows you to open a browser as per your choice. The tasks performed are as follows,
- Click buttons
- Enter information form
- Search specific information on web pages.
Install the selenium driver and provide the software interface to view the web pages.
Then click to install a driver.
Then save the downloaded driver to desired the folder and add file location to the PATH variable.
python selenium web scraping example :-
from selenium import webdriver
browser=webdriver.chrome ()
browser=webdriver.chrome ()
browser. get (‘https: //www.google.com’)
browser.quit ()
- Interacting with WebPages as:-
- Open webpage
- Interact with some way form
- Scroll right down to comment section.
Example:-
from selenium import webdriver
from selenium.webdriver.common.byimportBy ()
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser=webdriver.chrome (executable_path=”C://User/user_name/Desktop/Projects/rugby-websraper/chromedriver.exe”)
browser. get (‘https: //www.thegurdian.com/commentiesfree/2018/jun/21/matteo-salvini-threatening-minister-of-interior-police-protection-mafia’)
wait=WebDriverWait (browser. timeout)
element=wait. until (EC.element_to_be_clickable ((By.XPATH, COMMENTS_XPATH)))
element=browser.find_elemet_by_xpath (COMMENTS_XPATH)
element. Click ()
Web scarping use cases:-
It is powerful data collection tool used efficiently and the areas where they are employed are,
1. Trends:-It can be used to track the trends and stories there is no manpower to cover every story. It can be achieved more in the field.
2. Search:-
The use is to index the websites for them to appear the result. The scraping techniques are better than accurate that results in more accuracy.
3. Branding:-
It allows the marketing and communication of information about the brands. You can make awareness in people to feel about company and strategies around information.
4. ML:-
Machine learning is used in mining the data for building and training machine learning models.
5. Finance:-
Also used to scrape the data which affects the movement in the market.
Used to manage the data which is categorized correctly.
Packages and drivers used are as follows:-
The packages of the scraping are as follows,
- Chrome driver:-
The provides a platform to launch and perform tasks in a specified browser.
- Selenium package:-
It is used to automate web browser interaction from python.
- Extras:-
It is the resource at ReadTheDocs.
- Virtualenv:-
Used to create a python enviourement for our project.
- Tools and the libraries:-
The online libraries will provide programmers with a tool to quick up the scraper,
1) Scrapy:-
It is not just the python library but an entire data scraping framework that will provide spider bots.
Once the program is executed it wills request to the webpage and get HTML for URL from a list and parse it.
This method is used for indexing and tagging using the CSS along with Xpath.
We extract and store the link at the end with extension to images, pdf and create an HTML document.
2. BeautifulSoup:-
Used as a parsing library used for different parsing to extract data from XML documents and HTML.Also have the ability to parse and extract.
The beautifulSoup that contains all web data which is extracted.
Functions as find_all (), get_text () used for finding attribute and raw data you can read it.
Easy_install beautifulsoup4
Pip install beautifulsoup4
3. Lxml:-
It will provide the binding to fast xml and html library called as the libxml.
Also used internally by Beautifulsoup parser.
This library helps in linking the languages as extracting, processing, reading and HTML pages.
It will provide high-performance parsing with high speed and quality compared with beautiful soup.
The lxml will support xpath like selenium and make easy to parse XML pages.
You can also merge the functionality of Beautiful soup with lxml and support each other.
Python will give data extraction tool like Lxml and use python code for API.
Installation of lxml with the command is:
pip install lxml
Run it on Linux as,
Sudo pip install lxml
4. Selenium:-
Also called as the automation framework used when parsing the data from dynamically WebPages when the browser needs to be initialized.
It is also used for web scraping purpose.
It requires the driver to interface and browser such as chrome Driver for safari Driver 10.
Pip install selenium
5. Requests:-
Used to send the HTTP request which is popular and easy to use as compared to the standard library.
The request verifies SSL (Secure sockets layer for secure connection) which certifies for HTTPS like web browser.
The response is encoded HTML data and stored in request.
The text data can retrieve header data and JSON values. The request library is used to scrap our pages.
Pip install requests
There are libraries as scikit-learn,pandas and Numpy all that provide for storing and working with data received from data extraction tools.
- Steps for scraping with selenium:-
- You need to create a new project then create a file and name it setup.py and type selenium.
- Open a command line and you will need to create the virtual enviourement by typing commands.
- Then run dependency and do this by typing command in terminal.
- Now go back to the folder and create another file and add a name.
- From selenium import webdriver
- from selenium.webdriver.common.by import By
- From selenium.webdriver.common.byimportBy ()
- From selenium.webdriver.support.ui import WebDriverWait
- From selenium.webdriver.support import expected_conditions as EC
5. from selenium.common.exceptions import TimeoutException.Need to put in incognito mode and done in web driver by adding incognito argument.
6. a.option=webdriver.ChromeOptons ()
b.option.add_argument (“_incognito”)
7. Create a new instance, browser=webdriver.chrome (executable_path’/library/Application support/Google/chromedriver’, chrome_options=option)
8. Start the request to pass in website url used to scrape.
9. Need to create a user account with Github and easy process.
10. The data is ready to scrape from websites.
- Drivers to be downloaded:-
- Firefox gecko driver
- Chrome.
Python selenium web scraping example with Google
In this make a scripy that will load the Google search and make a query for “selenium”.
import time
from selenium import webdriver
from selenium.webdriver.comman.byimport By
from selenium.webdriver.support.ui import Webdriver Wait
from selenium.webdriver.support import expected_conditions as EC
from selenium.comman.expectations import TimeoutExpectation
def init_driver ():
driver=webdriver.Firefox ()
driver.wait=WebdDriverWait (driver, 5)
return driver
def lookup (driver, query):
driver.get (“http://www.google.com”)
try:
box=driver.wait.until (EC.presence_of_element_located (By.NAME,”q”))
button=driver.wait.until (EC.element_to_be_clickable (By_NAME,”btnk”))
box.send_keys (query)
button. Click ()
except TimeoutException:
print(“Box or Button not found in google.com”)
if_name_==_”main”_
driver=init_driver ()
lookup (driver,”selenium”)
time. sleep (5)
driver.quit ()
The init_driver will initialize the driver as it will create the driver instance. Also, add WebDriverWait function and attribute to the driver and access easily.
It will load the Google search page and wait for the query box element located for a clickable button.
As search button will move up from the screen,
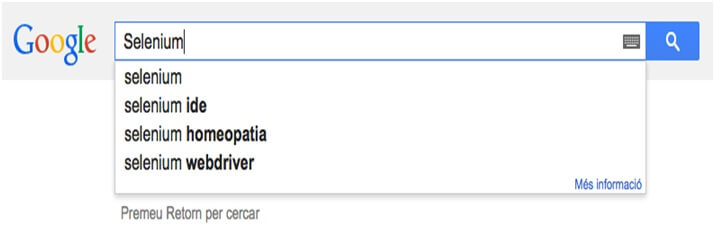
How code works:-
- First we use the .get () method to fetch the webpage.
- The WebDriverWait () then tell the webdriver for 15 sec and some condition is met.
- The wait condition is used by .until () method in which we are telling the web page for an object.
- Then finc_element_by_xpath and then .click () work to navigate section and click button.
Example:-
from urllib.request import urlopen
from bs4 import BeautifulSoup
html=urlopen (“https://ww.python.org/”)
res=BeautifulSoup (html.read (),”html5lib”);
print(res, title)
Result:-
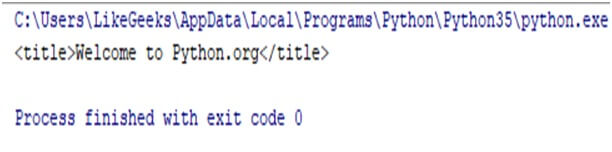
Benefits of web scraping:-
- You scrape competitor’s web page and analyze the data and see competitor’s clients are happy and all is free.
- The SE tool is like craps and crawls and entire web and process data for you and how to complete the field to be on top.
- There is use and scraped data means making money.
Handling the HTTP exception:
The example below will show the handling of HTTP exception,
From urllin.request import urlopen
From urllin.error import HTTPError
From bs4 import BeautifulSoup
Try:
Html=urlopem (“https://www.python.org/”)
Except HTTPERROR as e:
Print(e)
Else:
Res=Beautifulsoup (html.read (),”html5lib”)
Print(restitle)
Handling URL exception:-
We need to handle the exception and URL ERROR,
from urllib.request import urlopen
from urllib error import HTTPError
from urllib.error import URLError
from bs4 import BeautifulSoup
try:
html=urlopen (“https://www.python.org/”)
except HTTPErrror as e:
print(e)
except URLError:
print(“Server down or incorrect domain”)
else:
res=BeautifulSoup (html.read (),”html5lib”)
print(res.titles)
Scrap HTML Tags using class Attribute:-
It has function called find all which extracts the elements based on the attributes.
from urllib.request import urlopen
from urllib.error import URLError
from bs4 import BeautifulSoup
try:
html=urlopen (“https://www.python.org/”)
except HTTPError as e
print(e)
except URLError:
print(“server down or incorrect domain”)
else:
res=BeautifulSoup (html.read (),”html5lib”)
tags=res.findAll (“h2”, {“class”:”widgets-title”})
for tags in tags:
print(tag.getText ())
Output:-
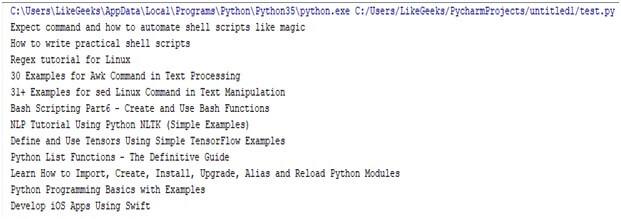
Advantages:-
- It will support the AJAX scraping and interaction.
- Also supports Xpath and CSS selectors.
- It is more or less cross-language API.
- It will focus on element inspector than source in xpath.
Disadvantages:-
- It is hard to install.
- The scraping overhead in the terms of memory, runtime, etc.
- The error message is hard to read.
- We need to use another library for constructing the URL query strings.
- Uses:-
- Data mining
- Contact scraping process
- Price comparison and change monitoring.
- Research
- Used in web data interaction.
- Gathering the real estate listing























