Types of machine learning algorithms
Types of machine learning algorithms : In this tutorial we have explained the types of machine learning algorithms and when you should use each of them. 1. Supervised Learning, 2. Unsupervised Learning, 3. Reinfor cement Learning, 4. Linear Regression and 5. Logistic Regression.
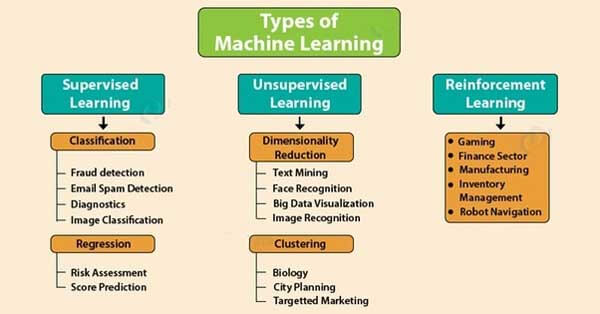
1. Supervised Learning:-
The algorithm will consist of the outcome variable which is predicted from a given set of predictors.
Using set of variables can generate a function that maps inputs to desired outputs.
The process continues until the model achieves a desired level of accuracy on the training data.
Example:-Regression, Decision Tree, etc.
2. Unsupervised Learning:-
The target outcome variable is not present to estimate and used for the clustering population in different groups.
It is used for segmenting customers in different groups.
Example:-Apriori algorithm, etc
3. Reinforcement Learning:
The machine will be trained to make specific decisions.
It is exposed to an environment where it trains itself using trial and error.
Example is Reinforcement Learning: Markov Decision Process
There is a list of algorithms as,
- Logistic regression
- Linear regression
- Decision Tree
- SVM
- Decision tree
- Navibe bayes
- KNN
4. Linear Regression:-
It is used to estimate the discrete values and based on set of independent variables. It will predict the probability of occurrence by fitting the independent variables, The probability of occurrence is by fitting data to logit function so called as the logit regression.
- Y – is the dependent Variable
- a – is the Slope
- X – is the independent variable
- b – and an intercept
The coefficient a and b are derived on minimizing the sum of squared difference of distance between data points and regression line.
Linear Regression is mainly of two types:-
- Simple Linear Regression
- Multiple Linear Regressions.
It is given by one independent variable and the Multiple Linear Regression is characterized by multiple independent variables.
We find the best fit line which you can fit a polynomial or curvilinear regression and known as polynomial.
x_train<-input_variables_values_training_datasets
y_train<-target_variables_values_training_datasets
x_test<-input_variables_values_test_datasets
x<-cbind (x_train, y_train)
linear<-mlm (y_train~, data=x)
summary (linear)
predicted=predict (linear, x_test)
5. Logistic Regression:-
X<-cbind (x_train, y_train)
Logistic<-glm(y_train~., data=x, family=’binominal’)
Summary(logistic)
Predicted=predict (logistic.x_test)
6. Decision Tree:-
We use the algorithm frequently so it is popular.
It is supervised learning algorithm and used for classification problems.
It works for both categorical and continuous dependent variables.
We will split the population into two or more homogeneous sets.
Example:-
Library(rpart)
X<-cbind (x_train, y_train)
Fit<-rpart (y_train~., data=x, method=”class”)
Summary(fit)
Predicted=predict (fit, x_test)
7. SVM (Support Vector Machine):-
Here we plot each data item as a point in n-dimensional space with the value of being the value of a particular coordinate.
We find some line that splits the data between the two differently classified groups of data.
It will be the line such that the distances from the closest point in each of the two groups will be farthest away.
8. Naive Bayes:-
It is based on Bayes’ theorem an assumption of independence between predictors.
The Naive Bayes classifier will assume the presence of a particular feature in a class is unrelated to the presence of any other feature.
This model is easy to build and useful for very large data sets.
Naive Bayes is known to outperform even highly sophisticated classification methods.
9. KNN (k- Nearest Neighbors):-
They are used for both classification and regression problems.
So it is widely used in classification problems in the industry.
K nearest neighbors is a simple algorithm that stores all available cases.
It will classify new cases by a majority vote of its k neighbors and KNN is easily mapped to our real lives.
10. K-Means:-
It is called an unsupervised algorithm that solves the clustering problem.
Its procedure follows a simple and easy way to classify a given data set through a certain number of clusters.
11. Random Forest:-
Random Forest is a trademarked term for an ensemble of decision trees here is a collection of decision trees.
The forest chooses the classification having the most votes.
12. Dimensionality Reduction Algorithms:-
There has been an exponential increase in data capturing at every possible stage.
The organizations are coming with new sources and capturing data in great detail.
13. LightGBM:-
The LightGBM is the boosting framework that uses tree-based learning algorithms.
Advantages:-
- Faster training speed and higher efficiency
- Lower memory usage
- Better accuracy
- Parallel and GPU learning supported
- Capable of handling large-scale data
Input data is called training data and the result is as spam/not-spam.























